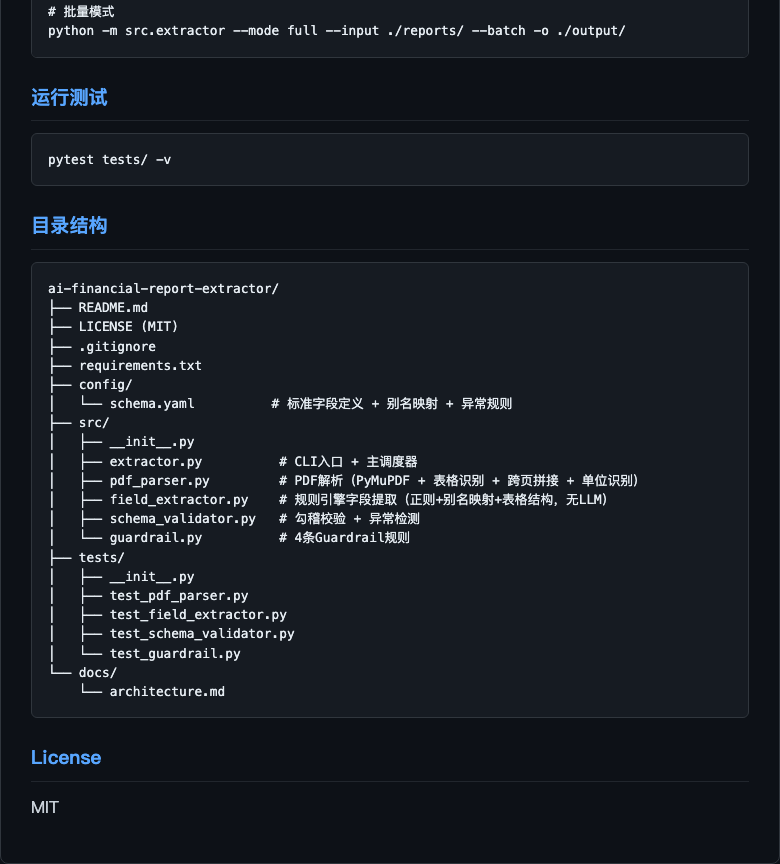
需求文档
纯本地规则引擎的财报数据结构化提取工具,零 LLM 依赖,离线可跑。支持三大报表 ~110 字段全量覆盖、勾稽校验、4 条 Guardrail 规则。


对话设计
三种提取模式:quick(20核心字段) / full(~110字段) / custom(自定义)。PDF 解析 → 规则引擎字段提取(schema.yaml 别名映射 + 正则匹配)→ Guardrail 合规 → 勾稽校验 → JSON 输出。


流程图
PDF 输入 → pdf_parser 解析(PyMuPDF + 表格识别 + 跨页拼接 + 单位检测)→ 字段提取(表格优先 → 文本兜底 → null)→ Guardrail(G1单位/G2空值/G3勾稽/G4来源)→ 输出 JSON。


架构图
分层架构:PDF 解析层(PyMuPDF)→ 规则引擎层(schema.yaml 驱动)→ Guardrail 层(4条规则)→ 校验层(勾稽 + 异常检测)→ 输出层(JSON)。

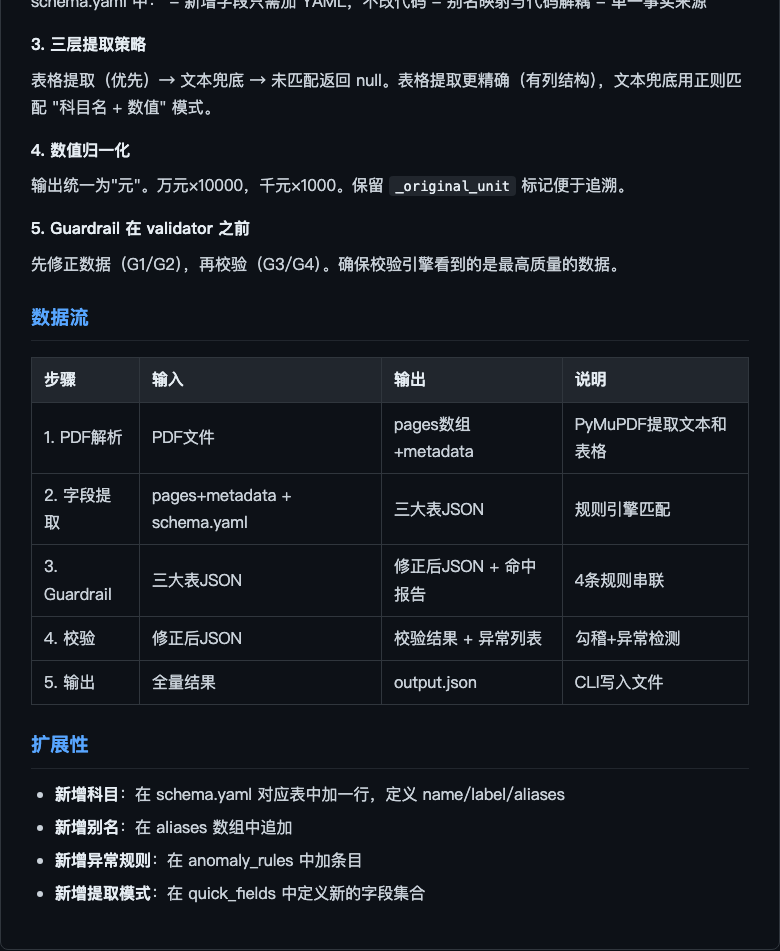
README
技术栈:Python + PyMuPDF + 纯规则引擎(无 LLM) + pytest
项目地址:GitHub